Sự đổi mới được giải phóng: Công nghệ NLP hấp dẫn nhất năm 2022
Ngày 25/01/2024 - 12:01Những tiến bộ này đã cải thiện đáng kể một loạt nhiệm vụ NLP, bao gồm mô hình hóa ngôn ngữ, dịch máy và phân tích tình cảm.
Năm 2022 là năm thành công nhất đối với NLP trong thời gian gần đây. Nhiều mô hình mới đã được tạo ra và rất nhiều cập nhật đã diễn ra. Tôi đã tổng hợp danh sách 10 tiến bộ NLP hàng đầu, hiệu quả và phổ biến nhất trong số tất cả các đột phá trong năm nay.
Cải thiện cách trình bày văn bản
Việc trình bày chính xác văn bản là cần thiết vì nó cho phép máy hiểu ý nghĩa và mục đích của văn bản, đồng thời cho phép chúng ta thực hiện nhiều tác vụ khác nhau như phân loại văn bản, dịch ngôn ngữ và tạo văn bản.
Như chúng ta biết để nhập dữ liệu văn bản vào các mô hình NLP, chúng ta cần chuyển đổi dữ liệu văn bản đó sang phần nhúng của chúng. Và kết quả của những mô hình này chỉ phụ thuộc vào những phần nhúng này.
Trong những năm qua, đã có những tiến bộ vượt bậc trong việc tìm ra cách biểu diễn vectơ của dữ liệu văn bản, bắt đầu từ việc sử dụng tần suất của các từ để tìm cách biểu diễn vectơ của chúng cho đến việc nhúng từ trong khi vẫn ghi nhớ mục đích và ý nghĩa của dữ liệu văn bản; những tiến bộ này đã dẫn đến những cải tiến đáng kể trong các nhiệm vụ NLP khác nhau.
Một số cột mốc quan trọng trong sự phát triển của tính năng nhúng từ bao gồm Word2vec, Glove, Fast text, Elmo, Bert, v.v.
Năm 2022 cũng là năm có những cải tiến và tiến bộ đáng kể trong lĩnh vực nhúng từ. Dưới đây là một số mô hình NLP đã được ra mắt trong năm nay.
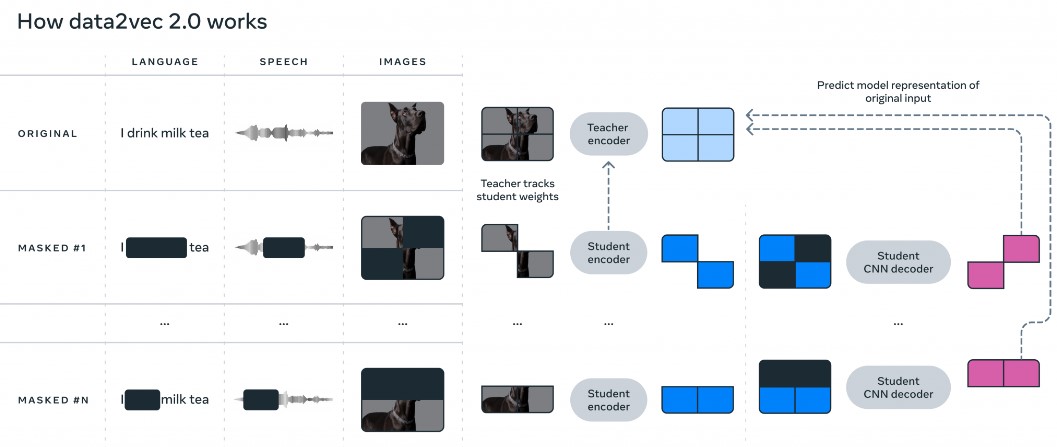
Dữ liệu2Vec 2.0
Data2Vec2.0 là bản phát hành cập nhật cho mẫu Data2vec. Data2vec là thuật toán học tự giám sát, nghĩa là nó có thể học từ hình ảnh, văn bản và giọng nói mà không cần nhãn rõ ràng. Các thuật toán học tự giám sát học bằng cách sử dụng cấu trúc vốn có của chính dữ liệu.
Data2Vec2.0 đã cho thấy kết quả to lớn đối với các tác vụ như hiểu văn bản, phân đoạn hình ảnh và dịch giọng nói.
Tương tự như thuật toán data2vec ban đầu, data2vec 2.0 dự đoán các biểu diễn dữ liệu theo ngữ cảnh, nghĩa là chúng tính đến toàn bộ dữ liệu huấn luyện.
Data2Vec2.0 là phiên bản cải tiến so với tất cả các phiên bản tiền nhiệm vì nó nhanh hơn bất kỳ mô hình nào khác và không ảnh hưởng đến độ chính xác.
Đối với giọng nói, bài kiểm tra được thực hiện trên điểm chuẩn nhận dạng giọng nói LibriSpeech, nơi nó hoạt động nhanh hơn 11 lần so với wav2vec 2.0 với độ chính xác tương tự. Đối với xử lý ngôn ngữ tự nhiên (NLP), việc đánh giá được thực hiện dựa trên điểm chuẩn Đánh giá hiểu ngôn ngữ chung (GLUE), đạt được độ chính xác tương tự như RoBERTa và BERT.
XEM THÊM: Tài khoản ChatGPT Plus giúp bạn làm việc nhanh hơn, thông minh hơn.
Mô hình nhúng mới và cải tiến
Text-embedding-ada-002 gần đây đã được openAI ra mắt. Nó đã vượt trội hơn tất cả các mô hình nhúng trước đây do openAI đưa ra.
Text-embedding-ada-002 được huấn luyện bằng cách sử dụng phương pháp học có giám sát, nghĩa là nó được huấn luyện trên tập dữ liệu được gắn nhãn bao gồm nội dung nhập văn bản và các mục tiêu tương ứng.
Mô hình sử dụng kiến trúc dựa trên máy biến áp được thiết kế để xử lý dữ liệu tuần tự như văn bản. Kiến trúc biến áp cho phép mô hình nắm bắt một cách hiệu quả mối quan hệ giữa các từ và cụm từ trong văn bản và tạo ra các phần nhúng phản ánh chính xác ý nghĩa của đầu vào.
Mô hình mới, nhúng văn bản-ada-002, thay thế năm mô hình riêng biệt để tìm kiếm văn bản, độ tương tự văn bản và tìm kiếm mã và có giá thấp hơn nhiều so với tất cả các mô hình trước đó.
Độ dài ngữ cảnh của mô hình mới được tăng lên, giúp thuận tiện hơn khi làm việc với các tài liệu lớn, trong khi kích thước nhúng của mô hình mới giảm xuống, giúp tiết kiệm chi phí hơn.
Tạo hình ảnh và video
Công nghệ đã giúp tạo ra hình ảnh và video dựa trên mô tả văn bản cơ bản về một tình huống hoặc hình ảnh. Tạo hình ảnh và video trong NLP là một lĩnh vực đang phát triển nhanh chóng với nhiều nghiên cứu và nhiều tiến bộ trong lĩnh vực này vẫn chưa có. Một số ứng dụng chính bao gồm tạo nội dung, quảng cáo và tạo hình ảnh chân thực.
Dưới đây là một số tiến bộ quan trọng đã diễn ra trong năm nay
Hình ảnh
Imagen, do Google phát triển và ra mắt vào năm 2022, là mô hình phổ biến văn bản thành hình ảnh. Nó nhận mô tả về hình ảnh và tạo ra hình ảnh thực tế.
Mô hình khuếch tán là mô hình tổng quát tạo ra hình ảnh có độ phân giải cao. Những mô hình này hoạt động theo hai bước. Ở bước đầu tiên, một số nhiễu gaussian ngẫu nhiên được thêm vào hình ảnh và sau đó ở bước thứ hai, mô hình học cách đảo ngược quá trình bằng cách loại bỏ nhiễu, từ đó tạo ra dữ liệu mới.
Imagen mã hóa văn bản thành các mã hóa và sau đó sử dụng mô hình khuếch tán để tạo ra hình ảnh. Một loạt các mô hình khuếch tán được sử dụng để tạo ra hình ảnh có độ phân giải cao.
Đây là một công nghệ thực sự thú vị vì bạn có thể hình dung tư duy sáng tạo của mình chỉ bằng cách mô tả một hình ảnh và tạo ra bất cứ thứ gì bạn muốn trong giây lát.
Bây giờ hãy để tôi cho các bạn xem hình ảnh đầu ra mà tôi đã sử dụng một văn bản nhất định
Dòng chữ: Bức tượng bằng đá cẩm thạch của DJ Koala ở phía trước bức tượng bàn xoay bằng đá cẩm thạch. Koala đeo tai nghe bằng đá cẩm thạch lớn.
Hình ảnh đầu ra:

Hình ảnh đầu ra của Koala DJ bởi Imagen
DreamFusion
DreamFusion, được Google phát triển vào năm 2022, có thể tạo các vật thể 3D dựa trên thao tác nhập văn bản.
Các đối tượng 3D được tạo ra có chất lượng cao và có thể xuất được. Chúng có thể được xử lý thêm bằng các công cụ 3D phổ biến.
Video một số hình ảnh 3D do DreamFusion sản xuất
Mô hình 3D được tạo dựa trên hình ảnh 2D từ mô hình hình ảnh tổng quát Imagen, do đó bạn cũng không cần bất kỳ dữ liệu đào tạo 3D nào cho mô hình.
DALL-E2
DALL-E2 là một hệ thống AI được phát triển bởi OpenAI và ra mắt vào năm 2022, có thể tạo ra hình ảnh và nghệ thuật chân thực dựa trên mô tả văn bản.
Chúng ta đã thấy những công nghệ tương tự, nhưng hệ thống này quá đáng để khám phá và dành chút thời gian. Tôi nhận thấy DALL-E2 là một trong những mẫu máy tốt nhất hiện nay, hoạt động trong lĩnh vực tạo hình ảnh.
Nó sử dụng GPT-3 được sửa đổi để tạo hình ảnh và được đào tạo trên hàng triệu hình ảnh từ internet.
DALL-E sử dụng kỹ thuật NLP để hiểu ý nghĩa của văn bản đầu vào và kỹ thuật thị giác máy tính để tạo ra hình ảnh. Nó được đào tạo trên một tập dữ liệu lớn về hình ảnh và các mô tả văn bản liên quan của chúng, cho phép nó tìm hiểu mối quan hệ giữa các từ và đặc điểm hình ảnh. DALL-E có thể tạo ra hình ảnh mạch lạc với văn bản đầu vào bằng cách tìm hiểu các mối quan hệ này.
Hãy để tôi chỉ cho bạn cách DALL-E2 hoạt động
Văn bản đầu vào – Gấu bông
Hình ảnh đầu ra-

Hình ảnh gấu bông Teddy do DALL-E2 sản xuất
Tác nhân đàm thoại
NLP đã giúp con người có thể tương tác với các ứng dụng máy tính theo cách họ làm với những người khác. Hầu hết các ứng dụng thương mại điện tử, nền tảng đặt hàng thực phẩm và nền tảng Giao hàng đều đang sử dụng chatbot cho người dùng của họ. Chúng có thể được tích hợp vào các trang web, ứng dụng nhắn tin và các nền tảng khác để cho phép người dùng tương tác với chúng bằng ngôn ngữ tự nhiên. Những tiến bộ gần đây trong NLP đã cho phép tạo ra các tác nhân đàm thoại thực tế và tiên tiến hơn.
Dưới đây là một số mẫu Conversational hàng đầu ra mắt năm 2022
LaMDA: Hướng tới các mô hình đối thoại an toàn, có căn cứ và chất lượng cao cho mọi thứ
LaMDA (Mô hình ngôn ngữ dành cho đối thoại và trả lời), do Google phát triển, là mô hình ngôn ngữ được thiết kế cho các tác vụ trả lời và hội thoại.
Mô hình này có thể được sử dụng theo nhiều cách khác nhau, chẳng hạn như chatbot, dịch vụ khách hàng, Trợ lý ảo, v.v.
Một trong những tính năng chính của LaMDA là khả năng tạo ra các phản hồi mạch lạc dựa trên văn bản đầu vào. Điều này đạt được thông qua việc sử dụng mô hình ngôn ngữ dựa trên máy biến áp được đào tạo trên một tập dữ liệu lớn về các cuộc hội thoại của con người. Mô hình có thể hiểu ngữ cảnh của cuộc trò chuyện và tạo ra các phản hồi phù hợp dựa trên nội dung của văn bản đầu vào.
LaMDA có thể tạo ra phản hồi chất lượng cao về nhiều chủ đề và câu hỏi mở.
Các nhà phát triển cũng lưu ý đến tính minh bạch của các phản hồi do mô hình tạo ra và nó tránh tạo ra nội dung xúc phạm và thiên vị.
Tôi chắc chắn các bạn sẽ muốn xem bản demo của con bot tuyệt vời này. Vì vậy, nó ở đây!
.png)
Cuộc trò chuyện với LaMDA
Trò chuyệnGPT
ChatGPT, được phát triển bởi OpenAI, vừa được phát hành vào cuối tháng 11 và là một trong những sản phẩm AI có tính lan truyền và thịnh hành nhất được ra mắt vào năm 2022. Hầu như tất cả các chuyên gia dữ liệu đều đang thử và nghiên cứu chatbot tuyệt vời này.
ChatGPT dựa trên mô hình ngôn ngữ GPT-3 (Generative Pre-training Transformer 3), một mô hình ngôn ngữ lớn, dựa trên Transformer được đào tạo trên một tập dữ liệu khổng lồ gồm văn bản do con người tạo ra.
Tài khoản ChatGPT Plus có thể tạo ra các phản hồi mạch lạc và có thể hiểu ngữ cảnh của cuộc trò chuyện cũng như tạo ra các phản hồi phù hợp dựa trên nội dung của văn bản đầu vào.
Nó được thiết kế để thực hiện các cuộc trò chuyện với mọi người. Một số tính năng của nó bao gồm trả lời các câu hỏi tiếp theo cho các chủ đề khác nhau.
Độ chính xác và chất lượng của các phản hồi do mô hình tạo ra là không thể so sánh với bất kỳ chatbot nào khác.
Đây là bản demo về cách ChatGPT hoạt động

Cuộc trò chuyện bằng chatGPT
Nhận dạng giọng nói tự động
Chúng ta có thể tương tác với các thiết bị, thiết bị gia dụng, Loa và Điện thoại nhờ sự hiện diện của các trợ lý ảo như Siri, Alexa, Google Assistant, v.v. Công nghệ cho phép chúng ta nói chuyện với các thiết bị diễn giải những gì chúng ta đang nói để trả lời các câu hỏi của chúng ta hoặc lệnh. Dưới đây là một số mô hình Nhận dạng giọng nói tự động cải tiến ra mắt vào năm 2022 đã đưa sự tiến bộ về công nghệ lên một tầm cao mới
Thì thầm
Whisper, được phát triển bởi OpenAI, là một công nghệ giúp chuyển đổi Lời nói thành văn bản.
Nó có nhiều mục đích sử dụng như Trợ lý ảo, phần mềm nhận dạng giọng nói, v.v. Hơn nữa, nó cho phép phiên âm bằng nhiều ngôn ngữ và dịch từ các ngôn ngữ đó sang tiếng Anh.
Whisper được đào tạo dựa trên 680.000 giờ dữ liệu đa ngôn ngữ và đa nhiệm được thu thập từ web. Việc sử dụng bộ dữ liệu lớn và đa dạng đã giúp tăng độ chính xác của mô hình.
Whisper sử dụng kiến trúc bộ mã hóa-giải mã trong đó âm thanh đầu vào được chia thành các đoạn có thời lượng 30 giây, được chuyển đổi thành biểu đồ phổ log-Mel và sau đó được chuyển vào bộ mã hóa. Bộ giải mã được đào tạo để dự đoán chú thích văn bản tương ứng.
Whisper có thể được đào tạo trên các tập dữ liệu lớn về các cặp giọng nói và phiên âm để cải thiện độ chính xác của nó và thích ứng với các giọng, ngôn ngữ và phong cách nói khác nhau.
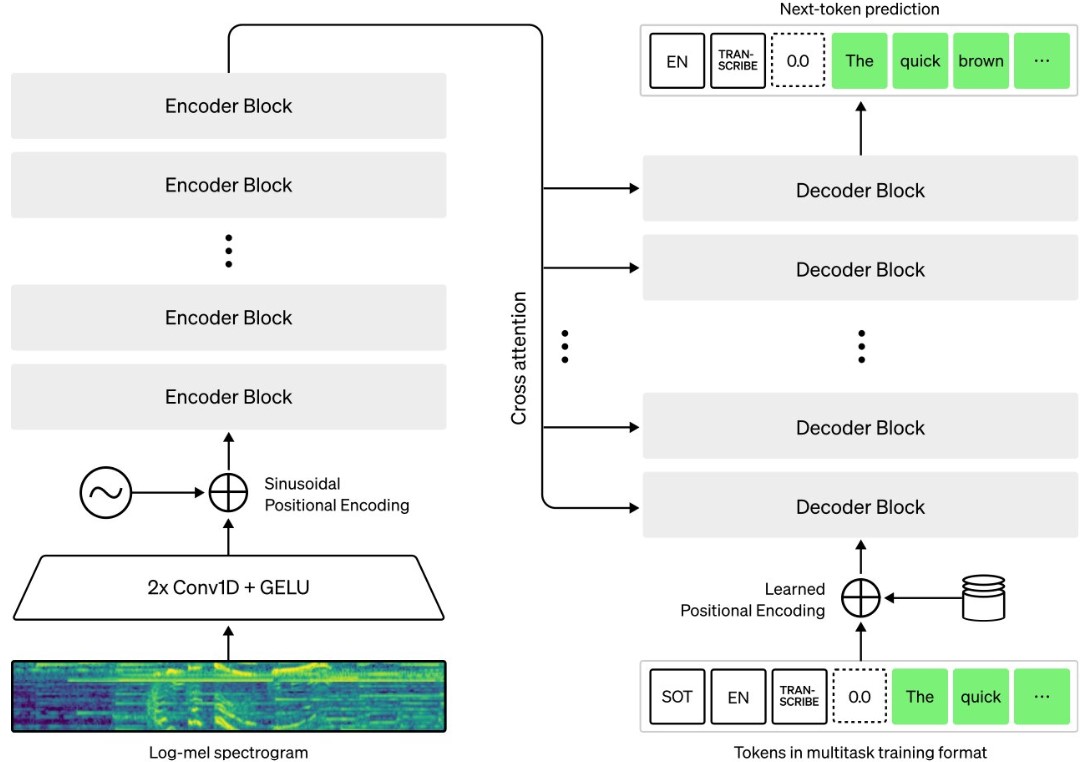
Kiến trúc của Whisper
Chuyển giao học tập trong NLP
Học chuyển giao là một cách tiếp cận phù hợp để xây dựng các mô hình hiệu suất cao. Trong học chuyển giao, mô hình được đào tạo trên các tập dữ liệu lớn và tổng quát, đồng thời được tinh chỉnh cho nhiệm vụ liên quan của chúng tôi. Nó đã được sử dụng rộng rãi trong xử lý ngôn ngữ tự nhiên (NLP) để cải thiện hiệu suất của các mô hình trên hầu hết mọi nhiệm vụ. Đã có nghiên cứu quan trọng vào năm 2022 xung quanh việc cải thiện các kỹ thuật học chuyển giao. Bây giờ chúng ta sẽ thảo luận về 2 bước đột phá hàng đầu trong lĩnh vực này.
Chuyển giao học tập trong NLP
Học chuyển giao là một cách tiếp cận phù hợp để xây dựng các mô hình hiệu suất cao. Trong học chuyển giao, mô hình được đào tạo trên các tập dữ liệu lớn và tổng quát, đồng thời được tinh chỉnh cho nhiệm vụ liên quan của chúng tôi. Nó đã được sử dụng rộng rãi trong xử lý ngôn ngữ tự nhiên (NLP) để cải thiện hiệu suất của các mô hình trên hầu hết mọi nhiệm vụ. Đã có nghiên cứu quan trọng vào năm 2022 xung quanh việc cải thiện các kỹ thuật học chuyển giao. Bây giờ chúng ta sẽ thảo luận về 2 bước đột phá hàng đầu trong lĩnh vực này.
Phân loại văn bản Zero-Shot với tính năng tự đào tạo
Do sự phát triển gần đây của các mô hình ngôn ngữ được đào tạo trước lớn, tầm quan trọng của việc phân loại văn bản không cần viết ngắn gọn đã tăng lên.
Đặc biệt, các bộ phân loại zero-shot được phát triển bằng cách sử dụng bộ dữ liệu suy luận ngôn ngữ tự nhiên đã trở nên phổ biến do kết quả đầy hứa hẹn và tính sẵn có của chúng.
Phương pháp tự đào tạo chỉ yêu cầu tên lớp và tập dữ liệu không được gắn nhãn mà không cần kiến thức chuyên môn về miền. Việc tinh chỉnh trình phân loại không cần bắn theo các dự đoán đáng tin cậy nhất của nó sẽ mang lại hiệu suất đáng kể trên nhiều tác vụ phân loại văn bản.
Bạn có thể đọc thêm về phương pháp này trong tài liệu hội nghị này .
XEM THÊM: Khám phá tiềm năng AI không giới hạn với tài khoản ChatGPT-4.
Cải thiện việc học tập ngắn gọn trong bối cảnh thông qua đào tạo tự giám sát
Học vài lần trong ngữ cảnh đề cập đến việc học một nhiệm vụ mới chỉ sử dụng một vài ví dụ trong bối cảnh của một nhiệm vụ lớn hơn, có liên quan. Một cách để cải thiện hiệu quả của việc học tập theo từng bối cảnh là thông qua việc sử dụng phương pháp đào tạo tự giám sát.
Học tập tự giám sát bao gồm việc đào tạo một mô hình thực hiện một nhiệm vụ chỉ sử dụng dữ liệu đầu vào và không có nhãn rõ ràng do con người cung cấp. Mục tiêu là tìm hiểu các cách biểu diễn có ý nghĩa của dữ liệu đầu vào có thể được sử dụng cho các tác vụ tiếp theo.
Trong bối cảnh học tập vài lần trong ngữ cảnh, đào tạo tự giám sát có thể được sử dụng để đào tạo trước mô hình về một nhiệm vụ liên quan, chẳng hạn như phân loại hình ảnh hoặc dịch ngôn ngữ, để tìm hiểu cách biểu diễn dữ liệu hữu ích. Sau đó, mô hình được đào tạo trước này có thể được tinh chỉnh cho nhiệm vụ học tập vài lần bằng cách chỉ sử dụng một vài ví dụ được gắn nhãn.
Phần kết luận
Tóm lại, những tiến bộ trong xử lý ngôn ngữ tự nhiên (NLP) là rất đáng kể trong những năm gần đây, dẫn đến những cải thiện đáng kể về khả năng hiểu và tạo ra ngôn ngữ của con người của máy tính. Những tiến bộ này đã được thực hiện bằng cách phát triển các thuật toán phức tạp hơn và sự sẵn có của lượng lớn dữ liệu và tài nguyên tính toán. NLP có nhiều ứng dụng, bao gồm dịch ngôn ngữ, phân loại văn bản, phân tích tình cảm và phát triển chatbot và nó có khả năng cách mạng hóa cách chúng ta tương tác với máy tính và truy cập thông tin. Khi công nghệ NLP tiếp tục được cải tiến, chúng ta có thể mong đợi được thấy những bước phát triển thú vị hơn nữa trong tương lai.














.jpg)





.jpg)

.jpg)

.jpg)
.png)


.png)








Bài viết liên quan
21/01/2024
21/01/2024
28/01/2024
22/01/2024
04/02/2024
21/02/2024