Tất cả những điều bạn cần biết về mô hình nền tảng
Ngày 22/01/2024 - 06:01Tôi chắc chắn, bạn đã làm được. Những công nghệ này đã gây bão trên toàn thế giới và trở thành một phần trong cuộc sống của chúng ta. Bạn đang thắc mắc những công nghệ này hoạt động như thế nào và điều gì khiến chúng có hiệu quả đáng kinh ngạc đến vậy? Câu trả lời nằm ở sức mạnh của Mô hình Nền tảng.
Chào mừng bạn đến với thế giới của Mô hình nền tảng - xương sống của trí tuệ nhân tạo hiện đại! Từ ChatGPT Plus đến Midjourney, những mô hình mạnh mẽ này đã cách mạng hóa cách máy móc hiểu và xử lý thông tin. Nhưng chính xác thì Mô hình nền tảng là gì và chúng hoạt động như thế nào?
Các mô hình nền tảng là động lực thúc đẩy thế hệ máy móc thông minh tiếp theo, trao quyền cho chúng nhìn, nghe và suy nghĩ theo những cách mà trước đây chỉ con người mới có thể làm được
– Demis Hassabis, Giám đốc điều hành của DeepMind
Trong bài đăng trên blog này, chúng ta sẽ tìm hiểu chi tiết về các mô hình Foundation. Chúng ta sẽ thảo luận về các loại mô hình Foundation khác nhau và hiểu quá trình đào tạo mô hình của chúng. Và cuối cùng hãy xem xét cách chúng ta có thể sử dụng chúng trong các nhiệm vụ ở tuyến sau. Cho dù bạn là nhà nghiên cứu AI hay chỉ mới bắt đầu với công nghệ Generative AI, bài đăng này có tất cả thông tin bạn cần để đưa sự hiểu biết của bạn về Mô hình nền tảng lên một tầm cao mới. Vì vậy, hãy thắt dây an toàn và sẵn sàng bắt đầu cuộc hành trình hấp dẫn vào trung tâm của trí tuệ nhân tạo !
Chúng tôi rất vui mừng được mời bạn tham dự Hội nghị thượng đỉnh DataHack 2023, diễn ra từ ngày 2 đến ngày 5 tháng 8 tại Trung tâm Hội nghị NIMHANS danh tiếng ở Bengaluru sôi động. Tại sao bạn nên ở đó, bạn hỏi? Bởi vì đây là NƠI dành cho những buổi hội thảo ấn tượng, những hiểu biết sâu sắc vô giá từ các chuyên gia trong ngành và cơ hội kết nối với những người cùng đam mê dữ liệu hơn bao giờ hết. Luôn đón đầu xu hướng, cập nhật những xu hướng mới nhất và mở ra những khả năng vô tận trong thế giới khoa học dữ liệu và AI. Hãy nắm bắt cơ hội đáng kinh ngạc này! Đánh dấu lịch của bạn, đảm bảo vị trí của bạn và sẵn sàng cho trải nghiệm khó quên tại Hội nghị thượng đỉnh DataHack 2023. Nhấp vào đây để biết thêm chi tiết!
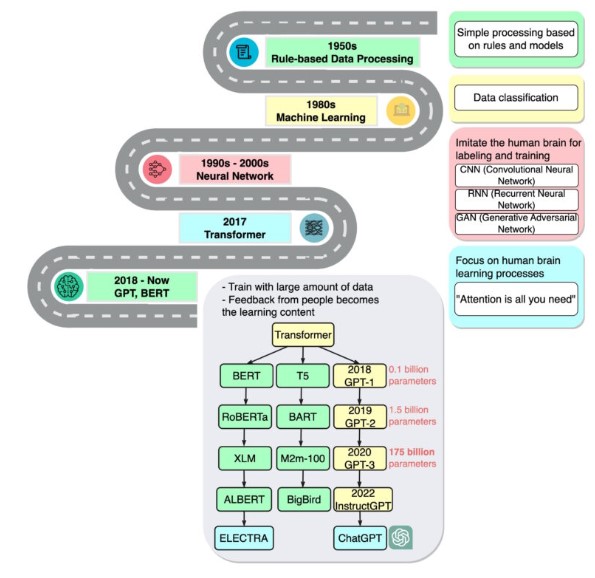
Lịch sử các mô hình nền tảng
Tất cả chúng ta có thể đã từng làm việc với các mô hình được đào tạo trước để giải quyết nhiều nhiệm vụ khác nhau liên quan đến văn bản và hình ảnh. Nhưng bạn có biết tại sao ngay từ đầu chúng tôi lại sử dụng các mô hình được đào tạo trước không? Lý do đằng sau nó là khả năng khái quát hóa tốt các nhiệm vụ khác. Những mô hình được đào tạo trước này được đào tạo trên một lượng lớn tập dữ liệu được gắn nhãn. Điều này hạn chế mô hình sử dụng khối lượng lớn dữ liệu chưa được gắn nhãn có sẵn. Điều này dẫn đến việc nghiên cứu xây dựng các mô hình có thể sử dụng các bộ dữ liệu không được gắn nhãn tức là các mô hình Foundation.
Thuật ngữ Mô hình nền tảng lần đầu tiên được đặt ra bởi nhóm AI của Stanford. Những mô hình này được chúng tôi gián tiếp gọi là Mô hình ngôn ngữ lớn hay còn gọi là LLM.
Transformers là bước đột phá đầu tiên trong lĩnh vực Xử lý ngôn ngữ tự nhiên vào năm 2017. Đây là một mô hình ngôn ngữ lớn dựa trên cơ chế chú ý. Nó được đào tạo trên các tập dữ liệu khổng lồ và được nhận thấy rằng nó có khả năng khái quát hóa tốt cho các nhiệm vụ khác bằng cách áp dụng thành công với dữ liệu hạn chế.
.png)
Điều này đã mở ra nghiên cứu về LLM để khám phá khả năng của nó. Năm 2018, 2 LLM phổ biến khác đã được Google và OpenAI giới thiệu: BERT và GPT.
Tiếp theo, một chủ đề nghiên cứu hấp dẫn đã xuất hiện liên quan đến việc nhân rộng các mô hình máy biến áp. Nó liên quan đến việc kiểm tra xem việc tăng kích thước và độ phức tạp của mô hình có nâng cao hiệu suất của mô hình hay tăng lượng dữ liệu sẽ nâng cao hiệu suất của mô hình hay không.
Vào năm 2019, Open AI đã phát hành GPT-2, LLM với 1,5 tỷ thông số và sau đó vào năm 2020, GPT-3 bằng cách tăng tỷ lệ GPT 2 lên 116 lần (với 175 tỷ thông số). Nó thật khổng lồ!
Nhưng mối lo ngại với những LLM này là những LLM này cũng có thể tạo ra những kết quả đầu ra có hại. Phải có cách để kiểm soát kết quả đầu ra do LLM tạo ra. Điều này dẫn đến công việc căn chỉnh các mô hình ngôn ngữ cho phù hợp với hướng dẫn. Cuối cùng, các mô hình hướng dẫn phù hợp như InstructGPT, ChatGPT, AutoGPT đã gây sốt trên toàn thế giới.
Mô hình nền tảng là gì?
Các mô hình nền tảng là các mô hình AI được đào tạo trên số lượng lớn bộ dữ liệu chưa được gắn nhãn có thể được sử dụng để giải quyết nhiều nhiệm vụ tiếp theo.

Ví dụ, các mô hình Foundation được đào tạo trên dữ liệu văn bản có thể được sử dụng để giải quyết các vấn đề liên quan đến văn bản như Trả lời câu hỏi, Nhận dạng thực thể được đặt tên, Trích xuất thông tin, v.v. Tương tự, các mô hình Foundation được đào tạo về hình ảnh có thể giải quyết các vấn đề liên quan đến hình ảnh như chú thích hình ảnh, đối tượng nhận dạng, tìm kiếm hình ảnh, v.v.
Chúng không chỉ giới hạn ở văn bản và hình ảnh. Họ có thể được đào tạo về các loại dữ liệu khác nhau như âm thanh, video, tín hiệu 3d.
Các mô hình Foundation đặt nền tảng vững chắc cho việc giải quyết các nhiệm vụ khác. Do đó, nhóm Stanford đã giới thiệu thuật ngữ “Mô hình nền tảng”. Điều tốt nhất về chúng là chúng có thể được huấn luyện dễ dàng mà không cần phụ thuộc vào tập dữ liệu được gắn nhãn.
Nhưng tại sao chúng ta lại cần Mô hình Nền tảng ngay từ đầu? Hãy tìm ra nó.
XEM THÊM: Bạn nghĩ AI đã đủ thông minh? Đợi đến khi bạn thử tài khoản ChatGPT-4
Tại sao lại là mô hình nền tảng?
Có 3 lý do chính cho sự cần thiết của các mô hình Foundation.
Tất cả hợp lại thành một
Các mô hình nền tảng cực kỳ mạnh mẽ. Họ đã loại bỏ nhu cầu đào tạo các mô hình khác nhau cho các nhiệm vụ khác nhau, nếu không sẽ xảy ra trường hợp này. Bây giờ, nó chỉ là một mô hình duy nhất cho tất cả các vấn đề.
Dễ dàng đào tạo
Các mô hình nền tảng rất dễ huấn luyện vì không phụ thuộc vào dữ liệu được dán nhãn. Và cần ít nỗ lực để điều chỉnh nó cho phù hợp với nhiệm vụ cụ thể của chúng ta.
Các mô hình nền tảng là bất khả tri về nhiệm vụ
Nếu không phải là các mô hình Foundation, chúng ta sẽ cần hàng trăm nghìn điểm dữ liệu được gắn nhãn để đạt được mô hình hiệu suất cao cho nhiệm vụ của mình. Nhưng khi sử dụng các mô hình Foundation, chỉ cần một vài ví dụ để điều chỉnh nó cho phù hợp với nhiệm vụ của chúng ta. Chúng ta sẽ thảo luận chi tiết về cách sử dụng các mô hình Foundation cho các nhiệm vụ của chúng ta sau.
Hiệu suất cao
Các mô hình nền tảng giúp chúng ta xây dựng các mô hình có hiệu suất rất cao cho các nhiệm vụ của mình. Kiến trúc State Of The Art (SOTA) cho các nhiệm vụ khác nhau trong Xử lý ngôn ngữ tự nhiên và Thị giác máy tính được xây dựng dựa trên các mô hình Foundation.
Các mô hình nền tảng khác nhau là gì?
Các mô hình nền tảng được phân loại thành các loại khác nhau dựa trên lĩnh vực mà chúng được đào tạo. Nhìn chung, nó có thể được chia thành 2 loại.
- Mô hình nền tảng cho xử lý ngôn ngữ tự nhiên
- Các mô hình nền tảng cho thị giác máy tính
Mô hình nền tảng cho xử lý ngôn ngữ tự nhiên
Mô hình ngôn ngữ lớn (LLM) là mô hình nền tảng cho xử lý ngôn ngữ tự nhiên. Các mô hình Ngôn ngữ lớn được đào tạo trên số lượng lớn bộ dữ liệu để tìm hiểu các mẫu và mối quan hệ có trong dữ liệu văn bản. Mục tiêu cuối cùng của LLM là học cách trình bày dữ liệu văn bản một cách chính xác.
Các công nghệ AI mạnh mẽ trong thế giới ngày nay đều dựa vào LLM. Ví dụ: ChatGPT sử dụng GPT-3.5 làm mô hình Foundation và AutoGPT, thử nghiệm AI mới nhất dựa trên GPT-4.
Dưới đây là danh sách các mô hình Nền tảng cho NLP: Transformers, BERT, RoBERTa, các biến thể của GPT như GPT, GPT-2, GPT-3, GPT-3.5, GPT-4, v.v.
Chúng ta sẽ thảo luận về cách đào tạo các Mô hình ngôn ngữ lớn này trong phần tiếp theo.
Các mô hình nền tảng cho thị giác máy tính
Mô hình khuếch tán là ví dụ phổ biến về mô hình nền tảng cho thị giác máy tính. Các mô hình khuếch tán đã nổi lên như một nhóm mô hình tạo sâu mới mạnh mẽ với hiệu suất hiện đại trong nhiều trường hợp sử dụng như tổng hợp hình ảnh, tìm kiếm hình ảnh, tạo video, v.v. Chúng có hiệu suất vượt trội so với các bộ mã hóa tự động, bộ mã hóa tự động biến thiên, GAN nhờ trí tưởng tượng và khả năng tổng hợp của nó khả năng.
Các mô hình chuyển văn bản thành hình ảnh mạnh mẽ nhất như Dalle 2 và Midjourney sử dụng các mô hình khuếch tán phía sau. Các mô hình khuếch tán cũng có thể hoạt động như mô hình Nền tảng cho NLP và các tác vụ tạo đa phương thức khác nhau như văn bản thành video, văn bản thành hình ảnh.
Bây giờ, chúng ta sẽ thảo luận về cách sử dụng các mô hình Foundation cho các nhiệm vụ tiếp theo.
Chúng ta có thể sử dụng các Mô hình Nền tảng như thế nào?
Cho đến nay, chúng ta đã thấy các mô hình Foundation và các loại mô hình khác nhau. Bây giờ, chúng ta sẽ xem cách sử dụng các mô hình này cho các nhiệm vụ tiếp theo sau khi đào tạo chúng.
Có 2 cách để làm điều đó. Tinh chỉnh và nhắc nhở
Sự khác biệt cơ bản giữa tinh chỉnh và nhắc nhở là
Việc tinh chỉnh sẽ tự thay đổi mô hình trong khi lời nhắc sẽ thay đổi cách sử dụng mô hình đó.
Tinh chỉnh
Kỹ thuật đầu tiên là tinh chỉnh các mô hình Foundation trên tập dữ liệu tùy chỉnh theo nhiệm vụ. Chúng tôi sẽ hoàn thiện mô hình cụ thể cho tập dữ liệu của chúng tôi. Chúng ta sẽ cần một tập dữ liệu bao gồm hàng trăm, hàng nghìn ví dụ cùng với các nhãn mục tiêu để tinh chỉnh mô hình.
Mô hình nền tảng được đào tạo trên tập dữ liệu miền chung. Bằng cách tinh chỉnh, chúng tôi đang điều chỉnh các tham số mô hình cụ thể cho tập dữ liệu của mình. Kỹ thuật này giải quyết vấn đề khó khăn khi có tập dữ liệu được gắn nhãn ở một mức độ nào đó nhưng không đầy đủ.
Đây là lời nhắc nhở!
Nhắc nhở
Nhắc nhở cho phép chúng ta sử dụng mô hình nền tảng để giải quyết một nhiệm vụ cụ thể chỉ thông qua một tập hợp các ví dụ. Nó không liên quan đến bất kỳ đào tạo mô hình nào. Tất cả những gì bạn cần làm là nhắc mô hình giải quyết nhiệm vụ. Điều này được gọi là học trong ngữ cảnh vì mô hình học từ ngữ cảnh, tức là đưa ra một tập hợp các ví dụ.
Tuyệt phải không?
Nhắc nhở liên quan đến việc cung cấp các tín hiệu hoặc điều kiện thiết kế cho mạng thông qua một số ví dụ để giải quyết các nhiệm vụ cụ thể. Như hình minh họa bên dưới, khi xử lý LLM, một tập hợp các ví dụ liên quan đến nhiệm vụ được cung cấp và mô hình dự kiến sẽ dự đoán mục tiêu bằng cách điền vào khoảng trống/mã thông báo tiếp theo trong câu.
Quan sát các mô hình ngôn ngữ học từ các ví dụ là một trải nghiệm thú vị vì chúng không được đào tạo rõ ràng để làm việc đó. Đúng hơn, quá trình đào tạo của họ xoay quanh việc dự đoán mã thông báo tiếp theo trong một câu nhất định. Điều này có vẻ gần như huyền diệu.
.png)
Các mô hình nền tảng được đào tạo như thế nào?
Như đã thảo luận, các mô hình của Foundation được đào tạo trên các tập dữ liệu không được gắn nhãn theo cách tự giám sát.
Trong học tập tự giám sát, không có tập dữ liệu được dán nhãn rõ ràng. Các nhãn được tạo tự động từ chính tập dữ liệu và mô hình được đào tạo theo cách có giám sát. Đó là sự khác biệt cơ bản giữa học có giám sát và học tự giám sát.
Có các mô hình nền tảng khác nhau trong NLP và thị giác máy tính nhưng nguyên tắc cơ bản của việc đào tạo các mô hình này là tương tự nhau. Bây giờ chúng ta hãy hiểu quá trình đào tạo.
Mô hình ngôn ngữ lớn
Như đã thảo luận, Mô hình ngôn ngữ lớn hay còn gọi là LLM là mô hình Nền tảng cho NLP. Tất cả các Mô hình ngôn ngữ lớn này đều được đào tạo theo cách tương tự nhưng khác nhau về kiến trúc mô hình. Mục tiêu học tập chung là dự đoán các từ còn thiếu trong câu. Mã thông báo bị thiếu có thể là mã thông báo tiếp theo hoặc bất kỳ vị trí nào trong văn bản.
Do đó, LLM có thể được phân thành 2 loại dựa trên mục tiêu học tập: LLM nhân quả và LLM ẩn giấu. Ví dụ: GPT là LLM nhân quả được đào tạo để dự đoán mã thông báo tiếp theo trong văn bản trong khi BERT là LLM ẩn được đào tạo để dự đoán mã thông báo bị thiếu xuất hiện ở bất kỳ đâu trong văn bản.
.png)
Mô hình khuếch tán
Hãy xem xét chúng ta có hình ảnh của một con chó, chúng ta áp dụng nhiễu gaussian vào nó, sau đó chúng ta thu được một hình ảnh không rõ ràng. Bây giờ, chúng tôi lặp lại quá trình này, áp dụng nhiễu gaussian nhiều lần cho hình ảnh, sau đó chúng tôi thu được một nhiễu hoàn chỉnh. Và hình ảnh là không thể nhận ra.

Có cách nào để lùi ảnh không rõ thành ảnh thật không? Đó chính xác là những gì mô hình khuếch tán làm.
Các mô hình khuếch tán học cách hoàn tác quá trình chuyển đổi hình ảnh nhiễu thành hình ảnh thực tế và nguyên bản.
Nói một cách đơn giản, các mô hình khuếch tán học cách khử nhiễu hình ảnh. Các mô hình khuếch tán được huấn luyện theo quy trình 2 bước:
- Khuếch tán chuyển tiếp
- Khuếch tán ngược
Khuếch tán chuyển tiếp
Trong bước khuếch tán về phía trước, hình ảnh huấn luyện được chuyển đổi thành hình ảnh hoàn toàn không thể nhận dạng được. Quá trình này là cố định và không yêu cầu bất kỳ mạng nào để học, không giống như Bộ mã hóa tự động biến đổi (VAE). Trong VAE, bộ mã hóa và bộ giải mã là 2 mạng khác nhau được đào tạo chung để chuyển đổi hình ảnh thành không gian tiềm ẩn và trở lại hình ảnh gốc.

Hãy tưởng tượng quá trình này tương tự như sự khuếch tán của mực trong nước. Khi mực khuếch tán vào nước, mực sẽ biến mất hoàn toàn. Chúng tôi sẽ không thể theo dõi nó.
Khuếch tán ngược
Đây là bước thú vị được gọi là Khuếch tán ngược. Đây là nơi việc học tập thực sự đang diễn ra.
Trong khuếch tán ngược, hình ảnh không thể nhận dạng được sẽ được chuyển đổi trở lại hình ảnh ban đầu. Mạng đơn được đào tạo để chuyển đổi nhiễu thành hình ảnh. Nó không thú vị sao?

Tiếp theo là gì?
Hiện tại, sự hiểu biết của chúng tôi về Mô hình Nền tảng đã được xác định rõ ràng. Giai đoạn tiếp theo bao gồm việc phát triển sự hiểu biết toàn diện và thành thạo về Mô hình nền tảng cho NLP hoặc Mô hình nền tảng cho Thị giác máy tính, tùy thuộc vào lĩnh vực bạn quan tâm.
Đối với các mô hình Foundation cho NLP, bạn cần xây dựng kiến thức chuyên sâu về LLM. Nó bao gồm việc xây dựng LLM từ đầu, đào tạo và tinh chỉnh LLM trên tập dữ liệu của bạn và nắm bắt các phương pháp hiệu quả nhất để triển khai chúng trong sản xuất.
Tương tự, đối với Mô hình nền tảng cho Tầm nhìn máy tính, bạn cần hiểu biết kỹ lưỡng về các mô hình phổ biến, bao gồm cả việc tạo ra chúng ngay từ đầu, đào tạo và tinh chỉnh trên bộ dữ liệu của bạn cũng như các chiến lược triển khai hiệu quả.
Đó là tất cả cho ngày hôm nay! Hẹn sớm gặp lại bạn ở bài viết tiếp theo.
Nhưng chờ đã, đừng rời đi vội! Nâng cấp trò chơi dữ liệu của bạn tại Hội nghị thượng đỉnh DataHack 2023, nơi chúng tôi đã tổ chức một loạt hội thảo sẽ khiến bạn kinh ngạc! Từ Nắm vững LLM: Đào tạo, Tinh chỉnh và Thực tiễn tốt nhất đến Khám phá AI sáng tạo bằng Mô hình Khuếch tán và Giải quyết các vấn đề trong Thế giới thực bằng Học tăng cường (và hơn thế nữa), những hội thảo này là tấm vé vàng để bạn mở ra giá trị to lớn. Hãy tưởng tượng bạn được đắm mình trong những trải nghiệm thực tế, đạt được những kỹ năng thực tế và kiến thức thực tế mà bạn có thể áp dụng ngay vào hành động. Ngoài ra, đây là cơ hội để bạn sánh vai với các nhà lãnh đạo trong ngành và mở ra những cơ hội nghề nghiệp mới thú vị. Hãy giành lấy vị trí của bạn và đăng ký ngay bây giờ để tham dự Hội nghị thượng đỉnh DataHack 2023 rất được mong đợi.














.jpg)





.jpg)

.jpg)

.jpg)
.png)


.png)








Bài viết liên quan
19/01/2024
01/03/2024
19/01/2024
20/02/2024
24/01/2024
24/02/2024